Un sistema de transcripción fonética automática, al que también denominaremos transcriptorfonetizador, pone en relación dos representaciones de un mismo texto, una representación ortográfica de entrada y una representación fonética de salida, a través de una operación informática de transducción. Un transcriptor ha de ser un sistema capaz de representar mediante símbolos fonéticos la pronunciación de los enunciados de una lengua con un margen de error virtualmente nulo y el menor coste informático, por lo que constituye un campo de trabajo en el que confluyen la investigación lingüística y el desarrollo de los medios técnicos apropiados para cumplir dicho objetivo. Un ejemplo es el tema que desarrollamos en estas páginas, el código fonético de la transcripción: será tarea de la lingüística decidir el repertorio de signos utilizados, que deberán responder a unos determinados objetivos, mientras que la informática ha de buscar los mecanismos idóneos para formalizar dichos signos. o
El alfabeto fonético de uso común en la lingüística, el Alfabeto Fonético Internacional (AFI), de la International Phonetic Association (IPA), ha de ser adaptado para la representación fonética del español (cf. De la Mota y Ríos, 1995):
(1) Las convenciones del AFI permiten la posibilidad de una doble representación de los sonidos. Así, es posible usar diacríticos para distinguir los sonidos resultantes de procesos de asimilación de los sonidos derivados directamente del fonema correspondiente. Esta ambigüedad de la codificación puede ser utilizada de modo ventajoso para el caso del español, pues, frente a la descripción tradicional, los sonidos palatalizados lateral y nasal son distintos a los sonidos lateral palatal y nasal palatal (cf. Martínez Celdrán, 1989: 51 y 91):
palatal | [ 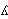 ] ] | calle |
| [ | peña | |
| palatalizado | [ | colcha |
| [ | conllevar |
La doble representación mediante signos y diacríticos permite indicar que la consonante velarizada nasal [
(2) El AFI no contempla un signo propio para todos los sonidos del español, se han de usar signos modificados con un diacrítico; son los casos de las articulaciones interdental, dental, africada y aproximante.
(2.1) Articulación interdental:
El punto de articulación interdental no ha sido previsto en el AFI. Se ha de utilizar un diacrítico, aplicado en los símbolos de las consonantes dentales, para indicar que se adelanta el punto de articulación. Así, por ejemplo, la consonante fricativa interdental sorda de la palabra zanahoria debería simbolizarse mediante el signo [  + ]. Como en español no existe la fricativa dental sorda [ ], no es necesario utilizar el diacrítico si se asigna el símbolo [ ] para la interdental.
+ ]. Como en español no existe la fricativa dental sorda [ ], no es necesario utilizar el diacrítico si se asigna el símbolo [ ] para la interdental.
(2.2) Articulación dental.
Para representar las consonantes oclusivas dentales [  ] (toro) y [
] (toro) y [ 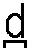 ] (conde) debería usarse el diacrítico que indica dentalización ya que los símbolos [
] (conde) debería usarse el diacrítico que indica dentalización ya que los símbolos [ 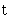 ] y [
] y [ 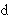 ] representan consonantes alveolares en el AFI. Como en español no existen dichas alveolares se puede usar los signos [ ] y [ ] sin diacrítico.
] representan consonantes alveolares en el AFI. Como en español no existen dichas alveolares se puede usar los signos [ ] y [ ] sin diacrítico.
(2.3) Articulación africada.
Puesto que [ ] y [ ] simbolizan consonantes alveolares en AFI, también en la representación de las consonantes africadas [ 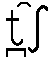 ] (coche) y [
] (coche) y [ 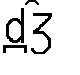 ] (cónyuge) se precisa un diacrítico que adelante el punto de articulación (del alveolar al dental). La solución es la misma que para [ ] y [ ].
] (cónyuge) se precisa un diacrítico que adelante el punto de articulación (del alveolar al dental). La solución es la misma que para [ ] y [ ].
(2.4) Articulación aproximante.
En la representación de las consonantes bilabial [ 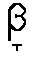 ],(lobo), dental [
],(lobo), dental [ 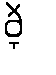 ] (codo) y velar [
] (codo) y velar [ 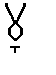 ] (dogo) se ha de usar un diacrítico, [
] (dogo) se ha de usar un diacrítico, [ ], para indicar que en español poseen un modo de articulación aproximante, y que no se trata de las consonantes fricativas [
], para indicar que en español poseen un modo de articulación aproximante, y que no se trata de las consonantes fricativas [ 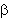 ], [
], [ 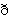 ] y [
] y [ 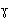 ] del AFI. Sólo la consonante aproximante velar posee un signo propio: [
] del AFI. Sólo la consonante aproximante velar posee un signo propio: [  ], por lo que puede ser representada mediante dos formas distintas. Hay una asimetría en el alfabeto: un signo propio para una aproximante y uso de diacrítico para las demás. Consideramos que la mejor solución es representar las aproximantes del español como [ ], [ ] y [ ], sólo aclarando que no representan sonidos fricativos.
], por lo que puede ser representada mediante dos formas distintas. Hay una asimetría en el alfabeto: un signo propio para una aproximante y uso de diacrítico para las demás. Consideramos que la mejor solución es representar las aproximantes del español como [ ], [ ] y [ ], sólo aclarando que no representan sonidos fricativos.
(3) Semivocales y semiconsonantes.
Con la adopción del inventario de símbolos que propone la Asociación Fonética Internacional se pierde la distinción gráfica entre semivocales y semiconsonantes, puesto que sólo puede utilizarse el diacrítico que indica "no silábico". No es conveniente utilizar los signos del alfabeto de la RFE con los que se representan las semiconsonantes ("j" y "w") para establecer una distinción entre ambas realizaciones, ya que en el AFI están destinados a representar otros sonidos. Siguiendo las convenciones de este alfabeto, la diferencia entre semiconsonante y semivocal se indicaría en la transcripción por el lugar de dichos sonidos en la sílaba en relación al núcleo:
[' | [' |
[' | [' |
A estos problemas lingüísticos se suman los del medio informático: la proliferación de diacríticos complica la codificación informática del alfabeto, como puede observarse en las propuestas de Esling (1988) y Esling y Gaylor (1993) para el AFI; no todos los sistemas operativos poseen fuentes fonéticas y la configuración de los teclados de los ordenadores no representa todos los símbolos y diacríticos de los alfabetos fonéticos comúnmente utilizados en el ámbito de la lingüística; no siempre los alfabetos fonéticos utilizados en los medios informáticos poseen representación para el repertorio de alófonos que se haya fijado en la transcripción, por ejemplo, el propuesto por Wells (1987 y 1990) para el desarrollo del proyecto SAM (Speech Assessmen Methods) es un alfabeto de enfoque fonológico.
Para la codificación de los signos fonéticos que representan los sonidos del español hemos creado un estándar que se ajusta a la configuración habitual de los teclados de los ordenadores. Estos signos se representan mediante los 125 primeros caracteres ASCII, excepto "ñ" y "ç". El alfabeto que proponemos es una respuesta a la necesidad de codificar los signos fonéticos para usos informáticos. La Tabla 1 contiene la adaptación de los signos del AFI para su uso en la transcripción fonética del español y la Tabla 2, la codificación informática de dichos signos.
El alfabeto que proponemos ha sido aplicado en el transcriptor que fonetiza el Diccionario Electrónico de Formas Simples Flexivas del Español (DEFSFE) (cf. Subirats, 1994), un sistema de transcripción fonética automática que genera la forma fónica -sonidos, división silábica y acentuación- que representa la pronunciación de los elementos léxicos; seguimos la norma de la variedad estándar de la lengua (cf. Ríos, 1993 y 1994). Desde el punto de vista formal, esta información fónica precede a la codificación alfanumérica que da cuenta de la categoría y de las propiedades morfológicas flexivas de cada palabra. La Tabla 3 es una muestra del DEFSFE.
TABLA 1. Adaptación del AFI al español.
CONSONANTES
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VOCALES
|
explotaron,es-plo-tá-ron,explotar.V1:IPIND3p explotas,es-pló-tas,explotar.VI:IPRES2s explotase,es-plo-tá-se,explotar.V1:SPIMB1s:SPIMB3s explotaseis,es-plo-tá-seIs,explotar.V1:SPIMB2p explotásemos,es-plo-tá-se-mos,explotar.V1:SPIMB1p explotasen,es-plo-tá-sen,explotar.V1:SPIMB3p explotases,es-plo-tá-ses,explotar.V1:SPIMB2s explotaste,es-plo-táç-te,explotar.V1:IPIND2s explotasteis,es-plo-táç-teIs,explotar.V1:IPIND2p explote,es-pló-te,explotar.V1:SPRES1s:SPRES3s:IIMPE2s exploté,es-plo-té,explotar.V1:IPIND1s explotéis,es-plo-téIs,explotar.V1:SPRES2p explotemos,es-plo-té-mos,explotar.V1:SPRES1p:IIMPE1p exploten,es-pló-ten,explotar.V1:SPRES3p:IIMPE2p explotes,es-pló-tes,explotar.V1:SPRES2s exploto,es-pló-to,explotar.V1:IPRES1s explotó,es-plo-tó,explotar.V1:IPIND3s expolia,es-pólIa,expoliar.V1:IPRES3s:IIMPE2s expoliaba,es-po-lIá-Ba,expoliar.V1:IPIMP1s:IPIMP3s expoliabais,es-po-lIá-BaIs,expoliar.V1:IPIMP2p expoliábamos,es-po-lIá-Ba-mos,expoliar.V1:IPIMP1p expoliaban,es-po-lIá-Ban,expoliar.V1:IPIMP3p expoliabas,es-po-lIá-Bas,expoliar.V1:IPIMP2s expoliación,es-po-lIa-zIón,expoliación.N23B:fs expoliaciones,es-po-lIa-zIó-nes,expoliación.N23B:fp expoliad,es-po-lIáT,expoliar.V1:IIMPE:2p expoliada,es-po-lIá-Da,expoliar.V1:PPfs expoliadas,es-po-lIá-Das,expoliar.V1:PPfp expoliado,es-po-lIá-Do,expoliar.V1:PPms expoliador,es-po-lIa-Dór,expoliador.N37A:ms,expoliador.A37A:ms expoliadora,es-po-lIa-Dó-ra,expoliador.N37A:fs,expoliador.A37A:fs expoliadoras,es-po-lIa-Dó-ras,expoliador.N37A:fp,expoliador.A37A:fp expoliadores,es-po-lIa-Dó-res,expoliador.N37A:mp,expoliador.A37A:mp expoliados,es-po-lIá-Dos,expoliar.V1:PPmp |
Δεν υπάρχουν σχόλια:
Δημοσίευση σχολίου